- Login to your server using putty and execute command “nmtui” to invoke the interface. If your machine is not in network you can login via console and follow the same steps mentioned below.
- If you don’t have the nmtui tool installed, you can install it using yum (Note: If you don’t want to install a new package in your server you can use nmcli for network configuration. Refer the post for how to configure network with nmcli )
[root@cloudvedas ~]# yum install NetworkManager-tui
[root@cloudvedas ~]# nmtui
- Once you get the interface you can navigate using Arrow keys , Tab key and make selection using “enter” key. So, using arrow key select “Edit a connection” and press enter.

- We have two network interfaces enp0s8 and enp0s3 . Today we will be configuring enp0s3. As enps0s8 is already configured and in use. So once highlighted enp0s3 go to “Add” and press enter.

- Select the type of connection. For this tutorial we are selecting “Ethernet”.

- Once in “Edit connection” section enter “Profile name” , “Device”. If you want static IP select “Manual” for IPv4 and select “Show”.
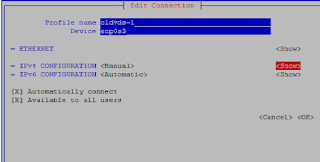
- Once you select “Show” enter your IP detail with subnet id. Here subnet id is /24 or 255.255.255.0 . Also enter gateway. If you want to use DNS enter DNS server details else leave it blank and select OK.

- Once the IP configuration is done select “OK” again. Now you can see the new connection that you have created. Select “Quit” to come out.
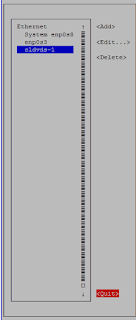
- Now let’s activate the connection. Execute “nmtui” in putty or console again and select “Activate a connection” and press Enter.
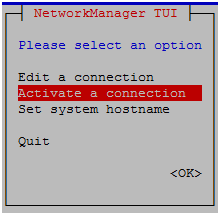
- Navigate with arrow key select the interface and then move right and Press enter on “Activate”. This will activate your interface as in image below.

- Check if the new IP is configured.
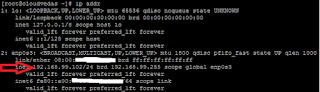
- Also let’s check in “nmcli” about the new connection.

Hope this post is helpful. Do let me know if you have any query.




